
In the early days of the internet, a common way to discover new websites was by either typing random words followed by “.com” on the navigation bar, or by following hyperlinks. Websites often had a section called “links” or “friends” where they featured other websites hand-picked by the webmaster.
Link banners, webrings, and visitor counters were staple elements of the web I grew up with. Even early social media like MySpace asked you to highlight a set of friends to showcase in your page. This was how discovery worked in the early days. Entirely hand-picked.
As an increasing number of people were making their own websites, the need for an index grew. Instead of trying to remember or guess the domain for a site, you could use a search engine to find it. Of course, the results initially were pretty bad. It didn’t always find what you were looking for, but it was better than nothing.
In a time where there was still competition in the search engine market, primitive versions of Yahoo! and Altavista helped me and my childhood friends find some cool websites about Oddworld species, emulators, quizzes, or obscure Pokemon red/blue tricks (I never got the Mew in the S.S. Anne truck — if it is real at all).
Google disrupted the space using their revolutionary algorithm, minimalistic design and high-quality results. We take it for granted now, but back then it felt like magic. Google was extremely good at not getting in the way. Their entire goal was for you to be in Google for the least amount of time because that meant that the user found what they were looking for and continued their journey.
After achieving total world domination, they started selling ad placement alongside its search results, making ads their main engine for growth. They would also give access to their network of advertisers in exchange for a percentage of the money generated. This shifted the company’s targets to capture more and more of their users’ clicks and behaviour online.
When ads became the economic engine of the web, people started manipulating the search engine algorithms to drive more traffic to their websites. Manipulation could turn previously obscure websites into overnight sensations. Pointless content (like the long stories before a recipe) were indicators that you’ve been a victim of this scheme. If your online community started getting flooded with spam, it was probably to generate traffic and backlinks to their scam of the day. What was set in motion was now impossible to stop. A better search score is more traffic to your site. More traffic to your site means more money.
To capitalize on the trend a new professional category was born. The SEO expert. Their goal? Manipulating search results. Some methods worked, others didn’t, but it made it so much harder for Google and others to filter out the bad actors. I have to confess, a lot of the SEO experts I’ve met were merely snake oil salesmen, but legend has it that some truly know what they are doing. Companies started polluting the internet with entire networks of low-quality websites linking to their main business to get a bigger share of the pie. Others specialized in creating a vast quantity of fake content to bury unwanted results from the first pages. Despite the numerous fixes deployed to combat this over the years, the arms race continues.
This monetization of the internet coincides with the death of the traditional forum. Forums were the places that would host most of our conversations online. They were full of knowledge easily devoured by search engines. They were slowly replaced by “worse” versions of them like Facebook groups, Slack, WhatsApp Groups, or Discord. These new alternatives, are inaccessible to a logged out user by default. That means that all those questions, answers, ideas, and discussions were now out of reach to outside users and search engines. Forums never fully went away, but they are not as mainstream as they used to be.
Google slowly started rolling out “featured snippets” on top of the search results, bypassing the need for you to visit actual websites. Each time a snippet rolls out, or the algorithm changes, it can make a certain type of websites go out of business. Maybe that’s good? Many of those sites only existed to capture traffic from Google, so removing them from the equation could be seen as a good thing. But when Google controls most of the web, if they decide to compete with you… Good luck. Have you noticed how many featured snippets there are now? Try searching for anything and you’ll most likely find the info you were looking for and then close the tab without visiting any of the results.
Google had it all, and there were no signs of anyone challenging their crown. Bing tried for a while, but it didn’t go as planned. So if a gigant like Microsoft can’t challenge Google Search, who is going to even attempt it now? Who has the resources to do it? Unfortunately for Google, A new challenger entered the arena: ChatGPT. It was the first real threat to conventional search engines. People started asking ChatGPT questions they would normally Google before. It shook the pillars of the internet. ChatGPT had an estimated 100 million monthly users within just two months of launching. Impossible to ignore. Google and everyone else tried to come up with their own versions of it in record time, which accelerated the AI hype.
Now, in 2024, we are in the peak of an AI bubble. Everyone promised investors millions of dollars in returns hoping to capture the next wave of technology. Once we all got used to ChatGPT and its clones, we saw what type of work or answers they can deliver. They mostly range from mediocre to completely incorrect. In its current state, it’s useful to find synonyms of words, or as a glorified autocomplete, but no matter how much tech bros try to convince you about its potential, it is clear that it needs more time in the oven. There is really only one thing it actually excels at: generating shitty content at a very high speed. Oh, and it is super cheap to do so!
Search engines, in an attempt to stay relevant to Wall Street, needed to find a way to add AI to their services. Instead of relying on “featured snippets” to host content from existing APIs they now try generate results on the fly. The downside of using LLMs to generate those answers is that the content might be completely made up, and in some cases even dangerous.
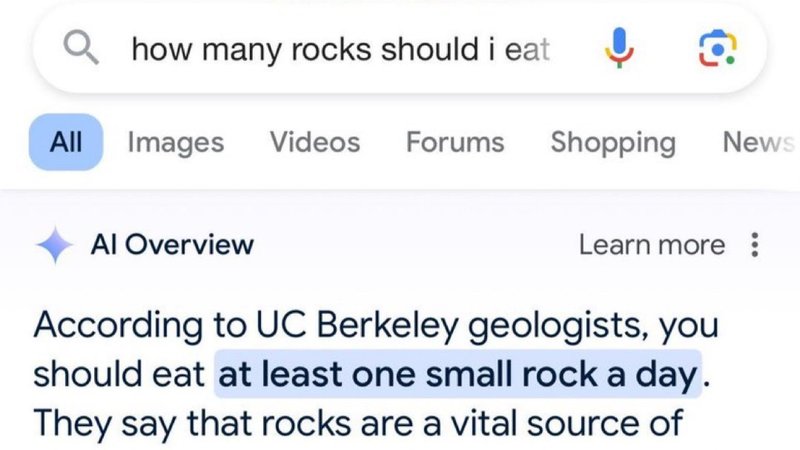
The web is slowly being flooded with AI content which is further lowering the quality of traditional search results. It is not uncommon to see people complaining about how bad their Google results are. And they are not wrong. They are worse. But I don’t believe there is a secret switch they can flip to make it better. There’s already too much noise, and the good conversations are locked away.
This does not only affect Google. DuckDuckGo, a search engine often presented as a privacy-focused alternative, is now also using AI to generate its own “assistant” answers. DuckDuckGo is typically the go-to alternative for people trying to escape Google. Their results, while more primitive, are decent enough to get by. The problem with the current model for search engines, is that, if everyone started using DuckDuckGo tomorrow, it would end up in the same position Google is now. It doesn’t matter who is behind the search engine, you are going to encounter the same issues. So, if even the quirky rebellious search engine is not safe from this, are we all doomed?
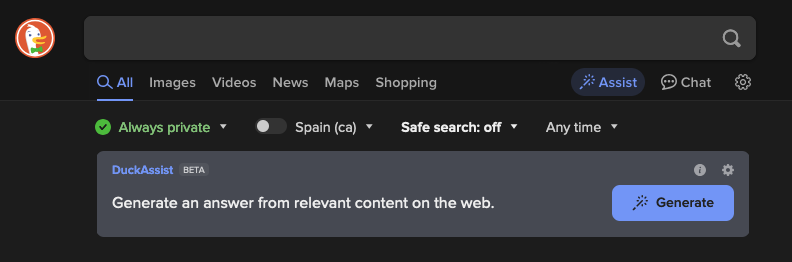
There seems to be a race to make the Dead Internet Theory a reality. It used to be an interesting thought experiment, but now it’s likely more true than not.
The dead Internet theory is an online conspiracy theory that asserts that the Internet now consists mainly of bot activity and automatically generated content manipulated by algorithmic curation to intentionally manipulate the population and minimize organic human activity.
Of course, like with every conspiracy theory, proponents always assume that this is done intentionally by a group of people with a perverse motive. In reality, this is done by a large group of independent individuals trying to make their own numbers go up. I don’t believe anyone intended to make it a reality, it just happened as a consequence of our relentless pursuit of infinite profit.
How many websites are out there that are just SEO farming? How many websites are copies of copies of recycled content hoping for a crumb of traffic to hit their ads? It really feels like the internet of humans is dying, and all we are left with is two lines of content wrapped in ads and clickbait. Many of us are using ad-blockers which hides the ugly truth. But as soon as you turn it off, you notice how bad things really are.
Can we go back to “the good old days”? It seems we’re already replicating the early internet in places like Reddit. Subreddits are like the forums mentioned earlier. Subreddits even have “visitor counters” and recommended communities picked by the moderators on a sidebar. I’m not a Reddit enthusiast, but people (myself included) are now appending reddit.com to their searches to get better results. We want to reach the knowledge that lives in it. It feels better than whatever we get, so why waste our time elsewhere.
But what makes Reddit content different from what Google returns? I believe the key difference is that Reddit is made and curated by humans. Users are the ones who submit content to it. They are the ones who upvote or downvote each entry. They are the ones who moderate it. The ones who direct people to the right destination. As humans, we can understand if a comment is sarcastically telling you to add non-toxic glue to your pizza, AIs might not. Yes, Reddit votes can be manipulated. Yes, there are a lot of echo chambers. Yes, there is misinformation. But even with all its flaws, I believe it is better than relying on the algorithm-seeking content creators. It is a vestige of the old internet that we all miss and love. At least for now.
At the end of the day, both Reddit and Google are aggregators of links that are ranked using different metrics. But Reddit doesn’t have robots adding every link that exists under the sun to their index. The users are the ones who decide what to share, what to include. The community makes it happen and curates it. Search engines will crawl anything and everything, regardless of its value.

This rant would be just sad without exploring solutions, so I’ll try. I’ve been thinking about this problem for a long time, and this is the first time I’m putting it in writing. My proposed solution may not be perfect, but it doesn’t need to be. I just hope I can start a conversation.
For me, good curation of the internet can only be achieved by humans. Algorithms are good tools to assist us, and they can be beautifully addictive in social media, but I don’t believe we should automate scraping the ENTIRE web if we want to build a truly useful modern search engine.
Funding for a new kind of search engine should not come from ad revenue. If the people behind this effort are incentivized by selling or managing ads, it will inevitably turn into a money-making machine first, search engine second. Community funded initiatives like Wikipedia, Linux, Blender, Ladybird, or Godot (where I spend most of my time at now) show us that it is possible to fund a big industry disrupting tool without relying on the ad-based internet. The conversation about properly funding the internet is much bigger than a single blogpost like this can cover, so maybe I’ll write a follow up about that in the future.
When I discuss ideas like this with close friends, they often think such a project is impossible. They believe it would require backing from a big company like Google, Facebook, or Microsoft. But I think it is possible, and I will never miss an opportunity to share this quote:
People overestimate what can be done in one year, and underestimate what can be done in ten. – Bill Gates
A new search engine is not out of reach. Communities of humans are extremely powerful and can achieve anything they set their minds to. In my eyes, the ideal search engine is one that indexes the web we love, and leaves the dead internet to the bots.
Note: I haven’t fact checked all of the statements in this entry. This is not meant to be a journalistic piece, it is just me organizing ideas. Because any mention of AI is controversial lately, I want to say that: I believe that using AI to enhance a human writer’s work is beneficial, but it shouldn’t replace human creativity. If the end result is good and properly supervised, it should be welcomed. I am not against LLMs, AI, or any other technology; I am against their misuse and the unethical methods companies employ to acquire training material.